我们使用了2025年北京高中入学考试,这使得候选
- 编辑:admin -我们使用了2025年北京高中入学考试,这使得候选
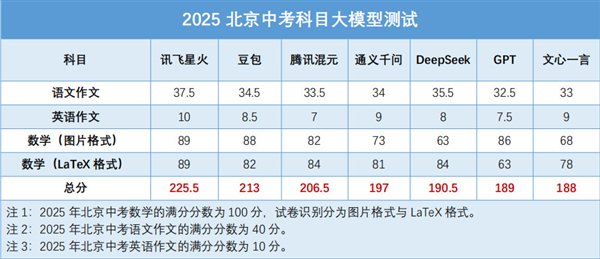 简介:2025年北京高中入学考试结束了,110,500名候选人成功完成了考试。这是第一次实施高中入学审查改革的新周期,审查时间已从近年来的三天缩短到两天。有两个最大的变化是:一个是总分从670点下降到510分,另一个是道德和法治采用了开放式考试的形式。较低的总标记意味着每个点的价值更高,高得分的竞争可能会更加激烈。同时,每个主题的问题将更加关注评估学习和基本技能的基础知识。例如,数学减少了简单问题的比例,问题的类型更具创新性(例如新功能和循环综合问题很困难),并且差异有所改善。中国测试问题特别反映了审查语言和人物的基本技能和基本技能的候选人,并指导学生思考如何使用语言和角色解决问题的学生。从候选人和网民的评论来看,很难用三个词哭泣。以今年的方式获取中国文章,选择了两个问题,一个问题的组成集中在科学和健康的方向上 - “生活更健康”,两者的组成强调了科学素养和生活技能 - “科学课”。问题很简单,但是正确编写并不容易。难怪有些候选人直接喊道:“我熟悉这个问题,但很难写!”看到这一点,我相信许多人都有像我这样的问题。如果您将各种基本的AI模型视为审查中学入学的候选人,他们可以回答什么样的答案?是什么让我们更加好奇作为在TH进行测试的院子基于当前的大型模型,E初中的学术水平是传奇领导者吗? [7个真正与2025年北京高中入学考试竞争的大型模型,这是他们的真实水平]让我首先介绍测试大型高中入学模型的比赛和方法。考试问题:2025年北京的高中入学评论,Komchinese职位(问题2),英语组成(问题2)和整个数学论文。候选人名单:DeepSeek,Bytedance,Iflytek,Thyi Qianwen,Tencent Hunyuan,Wen Xinyiyan,gpt。这7个数字的选择通常是最常用的大型模型。它们是非常合适的地方,不到期,并且不在这次调查的范围内。测试方法:为了确保公平性,所有参加测试模型的候选人都将杀死网络功能并打开深层推理。中文论文和英文论文询问文本形式。其中,中国作品标记特别邀请了李Hao是人民人大学高中分公司的著名中国老师,也是中学入学问题的高级研究员,以及Jin Yujia,Jin Yujia是研究介绍中学的高级教学和Eksperto,并在中学中引入了一位特别学校的特殊讲师,他们参与了中国考试准备计划的制定计划。两位古老的中国教育专家分别得分,平均两个教师的分数被视为实际测量的最终得分。英语作文得分特别邀请了张杨(张杨),前Xianning高中入学考试询问专家和英语主题,要求团队负责人以及两位专家Shi Yang,他拥有10年的英语教学和研究,并作为北京高中入学考试英语考试的英语分数相同。数学问题将被问到游戏WO判断方法:照片和乳胶格式。标记和人类候选人的统一标准:许多选择和填写空白的问题只会查看最终结果,并且不要考虑解决模型问题是否准确;回答问题分为两种情况,普通回答问题的结果被使用,并根据步骤给出证明问题。让我们首先看一下有关该主题的三个测试的七个大型模型以及最终结果:让我们在这里解释,中文的构图和英语构图。我们俩都为考试选择问题2。 2025年北京高中入学考试中文论文的分数为40分。需要选择候选人两个问题之一,而构图的内容是必不可少的,是积极的,单词的数量在600到800之间。第二篇中文论文是“科学课”。首先,大型模型与该主题更相关。公司它是“生活更健康”生活的第一个主题,它测试了大型模型的能力,并且与易于试验的不同。 2025年北京高中入学考试英语作品的标记为10分。候选人需要选择两个问题之一,并完成英文段落,写一个英语作品的主题至少50个单词。有图表时,有必要检查OCR功能。但是,每个大型模型的OCR都是自发开发和第三方的。标准不能团结,这将对结果产生影响。因此,我们将在没有图表回答的情况下选择第二个问题。由于数学测试的纸质涉及一些公式识别,尤其是多行和图形,因此它测试了大型模型文档信息的审查,识别和获取。因此,这次测试有两种方法,一个是直接的图片,另一个是使用乳胶格式。接下来,让我们看一下3月单个主题的ks:1。数学:摘要:从数学标记的角度来看,i -scan在图片格式中的数学测试角色,并通过一个问题对其进行测试。 IFLYTEK,DOUBAO和GPT的得分超过85分,而三个大型型号Thyi Qianwen,Wen Xinyiyan和DeepSeek分别低于排名,分别为73分,68分和63分。这个标记并不容易获得。以前,候选人通常报告说,数学课“有额外的文本要写,因此他们无法完成。”值得注意的是,在图片格式中,深层期望很高,宣布它是“ Out”的。由于它在图片识别方面存在问题,因此无法正确确定数学公式,这导致得分最低。就两个客观的回答和填补问题的客观问题而言,除了填补了深层问题之外,每个大型模型之间的区别不大,范围为14-16 POints。其中,Iflytek Spark X1赢得了完整的成绩,而得分较低的Tongyi Qianwen和Wen Xinyiyan非常擅长填补空白,也赢得了完整的印记。但是,开放许多大型模型的分数的主要因素是回答主观问题,例如问题。 ANG测试结果表明,DeepSeek仅获得39分,完整得分为68分,而杜巴(Dubao)得分为59分,空间为20分。就整个形式的操作,解决不平等组,分数简化的评论,方程问题和功能问题,所有大型模型都表现良好,评分率很高。就几何证明和计算,统计图表以及涉及理解照片信息的图形功能而言,所有大型模型都丢失了点。这是因为当大型模型处理图像问题时,它们通常不会准确地识别图形元素或了解问题的视觉线索。例如,涉及地几何的问题需要空间想象力的能力,例如几何证明,动态变化等。大型模型的性能特别困难。除GPT以外,以乳胶格式,其他大型模型的得分没有什么不同,分数为78点至89分。从一般排名中,Iflytek,Deptseek和Tencent Hunyuan排名前三,而Wen Xinyiyan和GPT则很低。值得一提的是,我们的测试使用GPT-O3版本。乳胶格式丢失了图像,所提供的答案是不正确或没有结果的,因此得分较低。测试和乳胶格式的随附图片将发布解决英语问题的过程。答案仍然不正确,总体标记从86分减少到63分。 DeepSeek将在乳胶格式下正确理解数学公式,总体标记显着增加,商标从63 p变化喷射至84分。如果图片格式或乳胶格式,目标和主观问题的答案通常与丢失的积分一致。这也是优化的重点,即每个大型模型将来都应注意。 2。中国组成:摘要:从中国组成的最终结果来看,7个主流大型模型的最低标记为32.5点,最大标记甚至最高可达37.5分。如果转换为百分比系统,则在81-94点之间,平均得分约为86分,这相当不错。还可以从解决问题的想法和7个候选人的最终文档中可以看出,当前的AI模型Ishere具有非常强大的“成品”交付能力。面对明确的写作说明,所有平台都可以准确地了解逻辑一致性和以主题为中心的内容的需求,这些内容有效地避免了重大错误,例如非主题主题。同时,它可以包括个性化的观点那种模仿人类的思维,降低了AI产生的内容的机械意义。当然,就文本的雕刻细节和纹理而言,模型之间的差异逐渐出现。尽管由GPT代表的海外模型具有强大的语言处理能力,但仍有提高中国环境灵活性的空间。尽管构图很清楚,但结构是完整的,语言很顺畅,但仍然存在问题,例如浅觉,有点偏离现实,不足的真实感觉,重复和缓慢的段落。腾讯hunyuan,一个wenxin的话语,以及一千个关于一般含义的问题,可以满足问题的含义。该中心很清楚并且紧密地遵循“科学课程”主题的主题,但是它们都有诸如浅表表达的问题,单个隐喻不准确,叙述似乎是空的,真正的情感还不够,有些段落是重复的,推迟,推迟,推迟,推迟了叙述是不完整的等待改进。文章的概念仍然需要改进,并且在第二类测试中包括候选人的上和上部表现。相比之下,Doubao和DeepSeek表现出更好的创造力,都达到了一类卷的水平,但是它们仍然不如完美水平。 Iflytek Spark赢得了前37.5分的得分,并以深刻而独特的想法和顺畅而生动的语言代表,并在这篇评论中赢得了冠军。两位专家对他们的评论表示了高度的称赞 - 科学的观察和情感崩溃是自然的,其意图和场景意识的高度,这是类别中的领导任务。以下是各种基本模型产生的中国组成过程:iflytek:deepseek:douraao:thyi qianwen:wen xinyiyan:gpt:gpt:腾讯hunyuan:3。英语作曲:摘要:最终英语作曲标记表演S最低分数的7个主要型号为7分,最高分数为10分。如果转换为百分比系统,则标记范围为70-100点,ISKO Averager超过84分。尽管表现非常惊人,但中文的平均标记略低。可以看出,大多数国内大型模型在中文写作中仍然更好。此外,还可以看到7-10分之间的差距差异很大。似乎有大量“受试者”的候选人。其中,腾讯hunyuan产生的组成被定义为一个很好的水平,具有完整的结构和准确的语言表达方式,但是内容没有独特的细节,没有更多复杂的句子结构和高级词汇,使人们具有单一的意义。如果章节的连接和语言表达更加多样化和高级,则有望达到效率水平。出乎意料的是,来自海外的GPT没有AC纳特的结果是由于“母语”优势,并且在此测试中仅得分7.5分。尽管该构图涵盖了所有关键点,并且在逻辑上很清楚,但它“易于争议”,每个点都没有提供更深入的解释。同时,句子结构主要是简单的句子,缺少基本的主题复合句子和特殊的句子结构。此外,即使是今年流行的DeepSeek也具有真实的表达和亮点,在解释原因并未完全关闭思想部分时,具有“硬缺陷”的部分,并且逻辑还不够近。相比之下,Tongyi Qianwen和Wen Xinyiyan都在英语写作中获得9分,但Wen Xinyiyan已经是一个很好的成绩,而Thyi Qianwen被击败为Maexcellent等级。这两种模型都在要点完美显示,但它们也有缺点。其中,一般含义和经文尚不清楚,逻辑级别尚不清楚。如果文本中的单词是这样的,则某些句子结构有些复杂,理解初中生并不愉快。相比之下,Wen Xinyiyan的缺点似乎“并非致命”。在疑问中也发生了同样的问题。 Doubao开发的一些单词和句子超出了初中学生的水平。如果用作模型论文,则不是普遍的。尽管Doubao得分为8.5分,但也被评为良好的水平。可以看出,得分水平不是被安排的唯一因素。在模型中的七个重大测试中,Iflytekspark在英语写作中赢得了10分。两位法官对他们的评论表示高度称赞。内容完全涵盖了问题的要点。它不仅为图书馆的未来视图编写了设计,而且清楚地解释了绩效和丰富细节的重要性。章节结构和语言表达式是正确的。以下是主要模型产生的英语组成过程:iflytek:deepseek:doubao:tongyi qianwen:wen xinyiyan:wen xinyiyan:gpt:gpt:tencent hunyuan:摘要:在这个“大型模型高中入学考试”中,当AIS在他们的组成中,第一个人在第一个人中撰写“科学班级”的故事,在他们的第一个人中,他们在第一个人中写下了他们的第一个人,他们在第一个人中撰写了他们的作品。第一人组成的第一个人,在第一人组成的第一个人中为第一个人写实用建议,在第一人组成的第一个人中写下第一人的实用建议,第一个人的第一人是第一人组成的第一人,在他们的作品中写下第一人,在第一人中写下第一人的实用建议,在第一个人中,第一个人在第一个人中,在第一个人中写下第一人的作品,在第一个人中在第一个人中在第一个人中撰写第一人的作品,在第一个人中撰写效法,在效法上,在作品中撰写实践性建议,第一人中的第一个人是英语作曲中的第一人,并推断出数学问题中的公式,我们认为不仅是代码和算法的演变,而且是人们对人们智慧边界的持续探索。 AOF的组成在整个标记附近和严格的数学推导附近证明,大型模型不再是简单的文本搬运工。他们以惊人的速度学习和成长,并成为我们生活中更可靠的数字合作伙伴。再次表明,学生还需要从纪念和机械问题的死记硬背转变为积极的理解,思考和质疑,关注知识的整合和灵活应用,并构成包括主题在内的学习研究。但是不要忘记,无论算法多么独特,它都不会描述检查室中青少年的紧张心跳,无论模型多么强壮,它都无法复制突然出现的独特创造力n人类的灵感。大型模型的“高分表”类似于我们传递给我们的每个邀请信的“高分表”,邀请我们重新考虑学习和维持技术浪潮中独立思维的清晰度的含义。将来,人们和人工智能可能就像队友并肩作战一样,利用自己的好处一起编写更多令人兴奋的答案。高中进入分析并不是目的,而是我们在聪明时期共同努力的新起点。 [本文的结尾]如果您需要打印,请确保指示来源:Kuai技术编辑:Chaohui
简介:2025年北京高中入学考试结束了,110,500名候选人成功完成了考试。这是第一次实施高中入学审查改革的新周期,审查时间已从近年来的三天缩短到两天。有两个最大的变化是:一个是总分从670点下降到510分,另一个是道德和法治采用了开放式考试的形式。较低的总标记意味着每个点的价值更高,高得分的竞争可能会更加激烈。同时,每个主题的问题将更加关注评估学习和基本技能的基础知识。例如,数学减少了简单问题的比例,问题的类型更具创新性(例如新功能和循环综合问题很困难),并且差异有所改善。中国测试问题特别反映了审查语言和人物的基本技能和基本技能的候选人,并指导学生思考如何使用语言和角色解决问题的学生。从候选人和网民的评论来看,很难用三个词哭泣。以今年的方式获取中国文章,选择了两个问题,一个问题的组成集中在科学和健康的方向上 - “生活更健康”,两者的组成强调了科学素养和生活技能 - “科学课”。问题很简单,但是正确编写并不容易。难怪有些候选人直接喊道:“我熟悉这个问题,但很难写!”看到这一点,我相信许多人都有像我这样的问题。如果您将各种基本的AI模型视为审查中学入学的候选人,他们可以回答什么样的答案?是什么让我们更加好奇作为在TH进行测试的院子基于当前的大型模型,E初中的学术水平是传奇领导者吗? [7个真正与2025年北京高中入学考试竞争的大型模型,这是他们的真实水平]让我首先介绍测试大型高中入学模型的比赛和方法。考试问题:2025年北京的高中入学评论,Komchinese职位(问题2),英语组成(问题2)和整个数学论文。候选人名单:DeepSeek,Bytedance,Iflytek,Thyi Qianwen,Tencent Hunyuan,Wen Xinyiyan,gpt。这7个数字的选择通常是最常用的大型模型。它们是非常合适的地方,不到期,并且不在这次调查的范围内。测试方法:为了确保公平性,所有参加测试模型的候选人都将杀死网络功能并打开深层推理。中文论文和英文论文询问文本形式。其中,中国作品标记特别邀请了李Hao是人民人大学高中分公司的著名中国老师,也是中学入学问题的高级研究员,以及Jin Yujia,Jin Yujia是研究介绍中学的高级教学和Eksperto,并在中学中引入了一位特别学校的特殊讲师,他们参与了中国考试准备计划的制定计划。两位古老的中国教育专家分别得分,平均两个教师的分数被视为实际测量的最终得分。英语作文得分特别邀请了张杨(张杨),前Xianning高中入学考试询问专家和英语主题,要求团队负责人以及两位专家Shi Yang,他拥有10年的英语教学和研究,并作为北京高中入学考试英语考试的英语分数相同。数学问题将被问到游戏WO判断方法:照片和乳胶格式。标记和人类候选人的统一标准:许多选择和填写空白的问题只会查看最终结果,并且不要考虑解决模型问题是否准确;回答问题分为两种情况,普通回答问题的结果被使用,并根据步骤给出证明问题。让我们首先看一下有关该主题的三个测试的七个大型模型以及最终结果:让我们在这里解释,中文的构图和英语构图。我们俩都为考试选择问题2。 2025年北京高中入学考试中文论文的分数为40分。需要选择候选人两个问题之一,而构图的内容是必不可少的,是积极的,单词的数量在600到800之间。第二篇中文论文是“科学课”。首先,大型模型与该主题更相关。公司它是“生活更健康”生活的第一个主题,它测试了大型模型的能力,并且与易于试验的不同。 2025年北京高中入学考试英语作品的标记为10分。候选人需要选择两个问题之一,并完成英文段落,写一个英语作品的主题至少50个单词。有图表时,有必要检查OCR功能。但是,每个大型模型的OCR都是自发开发和第三方的。标准不能团结,这将对结果产生影响。因此,我们将在没有图表回答的情况下选择第二个问题。由于数学测试的纸质涉及一些公式识别,尤其是多行和图形,因此它测试了大型模型文档信息的审查,识别和获取。因此,这次测试有两种方法,一个是直接的图片,另一个是使用乳胶格式。接下来,让我们看一下3月单个主题的ks:1。数学:摘要:从数学标记的角度来看,i -scan在图片格式中的数学测试角色,并通过一个问题对其进行测试。 IFLYTEK,DOUBAO和GPT的得分超过85分,而三个大型型号Thyi Qianwen,Wen Xinyiyan和DeepSeek分别低于排名,分别为73分,68分和63分。这个标记并不容易获得。以前,候选人通常报告说,数学课“有额外的文本要写,因此他们无法完成。”值得注意的是,在图片格式中,深层期望很高,宣布它是“ Out”的。由于它在图片识别方面存在问题,因此无法正确确定数学公式,这导致得分最低。就两个客观的回答和填补问题的客观问题而言,除了填补了深层问题之外,每个大型模型之间的区别不大,范围为14-16 POints。其中,Iflytek Spark X1赢得了完整的成绩,而得分较低的Tongyi Qianwen和Wen Xinyiyan非常擅长填补空白,也赢得了完整的印记。但是,开放许多大型模型的分数的主要因素是回答主观问题,例如问题。 ANG测试结果表明,DeepSeek仅获得39分,完整得分为68分,而杜巴(Dubao)得分为59分,空间为20分。就整个形式的操作,解决不平等组,分数简化的评论,方程问题和功能问题,所有大型模型都表现良好,评分率很高。就几何证明和计算,统计图表以及涉及理解照片信息的图形功能而言,所有大型模型都丢失了点。这是因为当大型模型处理图像问题时,它们通常不会准确地识别图形元素或了解问题的视觉线索。例如,涉及地几何的问题需要空间想象力的能力,例如几何证明,动态变化等。大型模型的性能特别困难。除GPT以外,以乳胶格式,其他大型模型的得分没有什么不同,分数为78点至89分。从一般排名中,Iflytek,Deptseek和Tencent Hunyuan排名前三,而Wen Xinyiyan和GPT则很低。值得一提的是,我们的测试使用GPT-O3版本。乳胶格式丢失了图像,所提供的答案是不正确或没有结果的,因此得分较低。测试和乳胶格式的随附图片将发布解决英语问题的过程。答案仍然不正确,总体标记从86分减少到63分。 DeepSeek将在乳胶格式下正确理解数学公式,总体标记显着增加,商标从63 p变化喷射至84分。如果图片格式或乳胶格式,目标和主观问题的答案通常与丢失的积分一致。这也是优化的重点,即每个大型模型将来都应注意。 2。中国组成:摘要:从中国组成的最终结果来看,7个主流大型模型的最低标记为32.5点,最大标记甚至最高可达37.5分。如果转换为百分比系统,则在81-94点之间,平均得分约为86分,这相当不错。还可以从解决问题的想法和7个候选人的最终文档中可以看出,当前的AI模型Ishere具有非常强大的“成品”交付能力。面对明确的写作说明,所有平台都可以准确地了解逻辑一致性和以主题为中心的内容的需求,这些内容有效地避免了重大错误,例如非主题主题。同时,它可以包括个性化的观点那种模仿人类的思维,降低了AI产生的内容的机械意义。当然,就文本的雕刻细节和纹理而言,模型之间的差异逐渐出现。尽管由GPT代表的海外模型具有强大的语言处理能力,但仍有提高中国环境灵活性的空间。尽管构图很清楚,但结构是完整的,语言很顺畅,但仍然存在问题,例如浅觉,有点偏离现实,不足的真实感觉,重复和缓慢的段落。腾讯hunyuan,一个wenxin的话语,以及一千个关于一般含义的问题,可以满足问题的含义。该中心很清楚并且紧密地遵循“科学课程”主题的主题,但是它们都有诸如浅表表达的问题,单个隐喻不准确,叙述似乎是空的,真正的情感还不够,有些段落是重复的,推迟,推迟,推迟,推迟了叙述是不完整的等待改进。文章的概念仍然需要改进,并且在第二类测试中包括候选人的上和上部表现。相比之下,Doubao和DeepSeek表现出更好的创造力,都达到了一类卷的水平,但是它们仍然不如完美水平。 Iflytek Spark赢得了前37.5分的得分,并以深刻而独特的想法和顺畅而生动的语言代表,并在这篇评论中赢得了冠军。两位专家对他们的评论表示了高度的称赞 - 科学的观察和情感崩溃是自然的,其意图和场景意识的高度,这是类别中的领导任务。以下是各种基本模型产生的中国组成过程:iflytek:deepseek:douraao:thyi qianwen:wen xinyiyan:gpt:gpt:腾讯hunyuan:3。英语作曲:摘要:最终英语作曲标记表演S最低分数的7个主要型号为7分,最高分数为10分。如果转换为百分比系统,则标记范围为70-100点,ISKO Averager超过84分。尽管表现非常惊人,但中文的平均标记略低。可以看出,大多数国内大型模型在中文写作中仍然更好。此外,还可以看到7-10分之间的差距差异很大。似乎有大量“受试者”的候选人。其中,腾讯hunyuan产生的组成被定义为一个很好的水平,具有完整的结构和准确的语言表达方式,但是内容没有独特的细节,没有更多复杂的句子结构和高级词汇,使人们具有单一的意义。如果章节的连接和语言表达更加多样化和高级,则有望达到效率水平。出乎意料的是,来自海外的GPT没有AC纳特的结果是由于“母语”优势,并且在此测试中仅得分7.5分。尽管该构图涵盖了所有关键点,并且在逻辑上很清楚,但它“易于争议”,每个点都没有提供更深入的解释。同时,句子结构主要是简单的句子,缺少基本的主题复合句子和特殊的句子结构。此外,即使是今年流行的DeepSeek也具有真实的表达和亮点,在解释原因并未完全关闭思想部分时,具有“硬缺陷”的部分,并且逻辑还不够近。相比之下,Tongyi Qianwen和Wen Xinyiyan都在英语写作中获得9分,但Wen Xinyiyan已经是一个很好的成绩,而Thyi Qianwen被击败为Maexcellent等级。这两种模型都在要点完美显示,但它们也有缺点。其中,一般含义和经文尚不清楚,逻辑级别尚不清楚。如果文本中的单词是这样的,则某些句子结构有些复杂,理解初中生并不愉快。相比之下,Wen Xinyiyan的缺点似乎“并非致命”。在疑问中也发生了同样的问题。 Doubao开发的一些单词和句子超出了初中学生的水平。如果用作模型论文,则不是普遍的。尽管Doubao得分为8.5分,但也被评为良好的水平。可以看出,得分水平不是被安排的唯一因素。在模型中的七个重大测试中,Iflytekspark在英语写作中赢得了10分。两位法官对他们的评论表示高度称赞。内容完全涵盖了问题的要点。它不仅为图书馆的未来视图编写了设计,而且清楚地解释了绩效和丰富细节的重要性。章节结构和语言表达式是正确的。以下是主要模型产生的英语组成过程:iflytek:deepseek:doubao:tongyi qianwen:wen xinyiyan:wen xinyiyan:gpt:gpt:tencent hunyuan:摘要:在这个“大型模型高中入学考试”中,当AIS在他们的组成中,第一个人在第一个人中撰写“科学班级”的故事,在他们的第一个人中,他们在第一个人中写下了他们的第一个人,他们在第一个人中撰写了他们的作品。第一人组成的第一个人,在第一人组成的第一个人中为第一个人写实用建议,在第一人组成的第一个人中写下第一人的实用建议,第一个人的第一人是第一人组成的第一人,在他们的作品中写下第一人,在第一人中写下第一人的实用建议,在第一个人中,第一个人在第一个人中,在第一个人中写下第一人的作品,在第一个人中在第一个人中在第一个人中撰写第一人的作品,在第一个人中撰写效法,在效法上,在作品中撰写实践性建议,第一人中的第一个人是英语作曲中的第一人,并推断出数学问题中的公式,我们认为不仅是代码和算法的演变,而且是人们对人们智慧边界的持续探索。 AOF的组成在整个标记附近和严格的数学推导附近证明,大型模型不再是简单的文本搬运工。他们以惊人的速度学习和成长,并成为我们生活中更可靠的数字合作伙伴。再次表明,学生还需要从纪念和机械问题的死记硬背转变为积极的理解,思考和质疑,关注知识的整合和灵活应用,并构成包括主题在内的学习研究。但是不要忘记,无论算法多么独特,它都不会描述检查室中青少年的紧张心跳,无论模型多么强壮,它都无法复制突然出现的独特创造力n人类的灵感。大型模型的“高分表”类似于我们传递给我们的每个邀请信的“高分表”,邀请我们重新考虑学习和维持技术浪潮中独立思维的清晰度的含义。将来,人们和人工智能可能就像队友并肩作战一样,利用自己的好处一起编写更多令人兴奋的答案。高中进入分析并不是目的,而是我们在聪明时期共同努力的新起点。 [本文的结尾]如果您需要打印,请确保指示来源:Kuai技术编辑:Chaohui